forskning
AI-en din forstår dansk bedre enn nynorsk. Vi halverte gapet.. på én kveld.
Hvordan en pinlig enkel KL-loss og 1 000 paragrafer fra Målfrid lukket halve nynorsk-gapet i Qwen.
 Einar K. HoltFounder & Partner · 9. mai 2026 · 14 min lesing
Einar K. HoltFounder & Partner · 9. mai 2026 · 14 min lesingHver eneste Qwen-modell vi testet svarer 9–12 prosentpoeng dårligere på nynorsk enn på bokmål. Det er ikke et lite avvik — det er at AI-en gjør LO-skole-feil hver gang en bruker skriver i målform som halve Vestlandet bruker. Her er hva vi prøvde, hva som funket, og hva som spektakulært gikk i bakken.
Det er en liten ting du sannsynligvis ikke har lagt merke til når du tester den nye GPT-en din eller den lokale Qwen-modellen din: hvis du bytter fra bokmål til nynorsk, blir den dummere. Ikke litt. Ikke i prinsippet. Mye, og målbart.
På NorEval, det er den faglige Norwegian-benchmark-suiten fra Mikhailov et al. (ACL 2025) så har hver eneste Qwen 2.5-variant vi testet et 9–12 prosentpoengs gap mellom bokmål og nynorsk på sunn fornuft-oppgaver. Bokmål vinner. Hver gang.
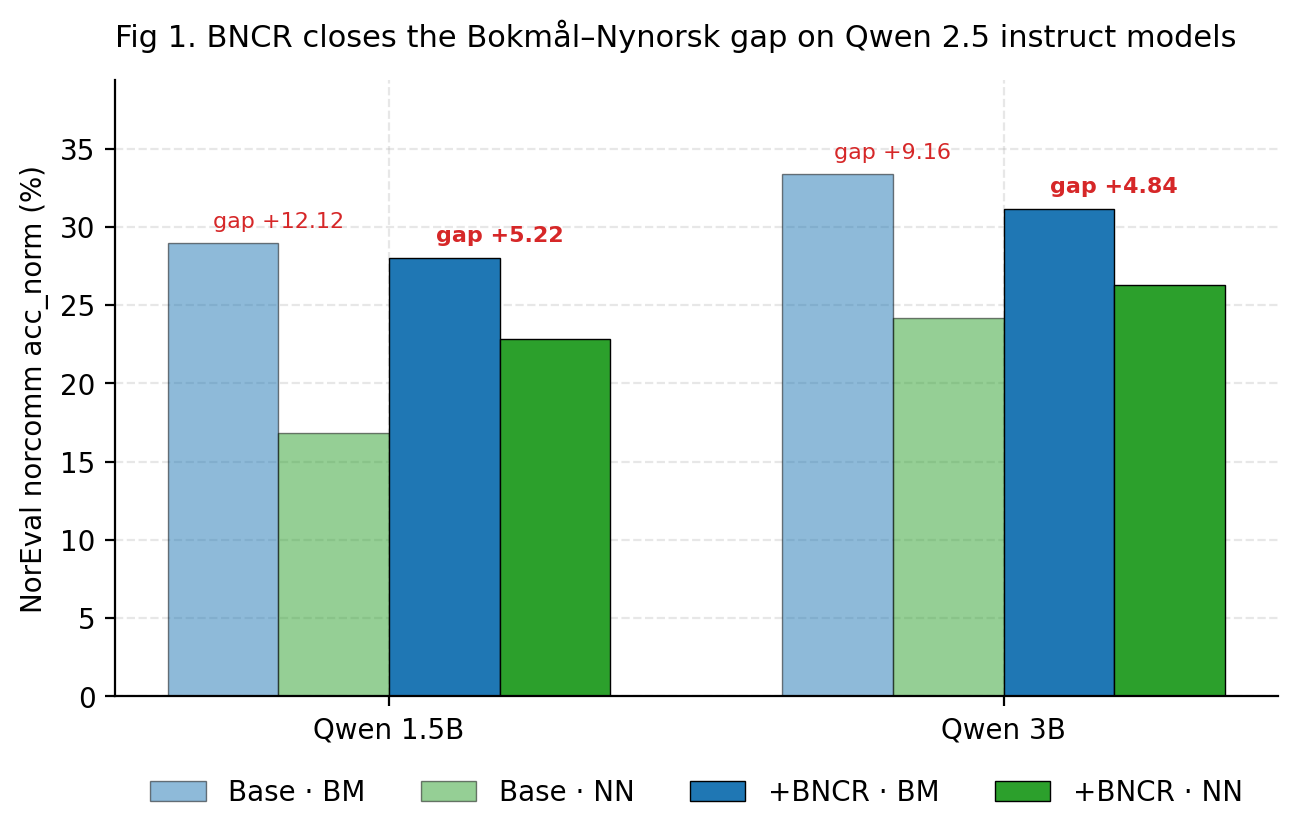
For Qwen 2.5-1.5B-Instruct: bokmål 28,96 %, nynorsk 16,84 %. Det er ikke "modellen er litt rusten på nynorsk", det er "modellen havarerer på nynorsk."
Og dette er, vel, ironisk, fordi NorMistral-7B-warm, den eneste norsktrente modellen i sammenligningen vår — er bedre på nynorsk-idiomer (68 % F1) enn alle de internasjonale modellene er på bokmål. Det er noen som har skjønt poenget. Det er bare ikke Alibaba.
Hva er det egentlig som er galt?
Treningsdataene. Bokmål er overrepresentert i alt som heter Common Crawl, Wikipedia, og bedriftsdokumenter. Nynorsk eksisterer mer eller mindre som et statistisk fotnotespor i pretraining-blandingene — hvis det engang er klassifisert riktig. (FastText sin lid.176, som hele bransjen bruker for språkdeteksjon, kan ikke skille bokmål fra nynorsk i det hele tatt. De får begge etiketten 'no' og settes i samme bøtte. Effektivt.)
Resultatet: modellen kan hjelpe en saksbehandler i Hordaland med å skrive et avslagsbrev, men hvis hun skriver kommandoen sin på nynorsk, går kvaliteten merkbart ned.
Mållovens §1 sier likebehandling. AI-distribusjonene i offentlig sektor i 2026 leverer ikke det.
Vår idé: la oss bare trene den til å bli enig med seg selv
Tenk deg dette: du har samme spørsmål, men i to varianter, én på bokmål, én på nynorsk. Modellen burde åpenbart svare det samme på begge. Det er det samme spørsmålet.
Men den gjør ikke det. Distribusjonen over neste-token er forskjellig avhengig av hvilken målform du brukte. Så: hva om vi eksplisitt tvinger den til å produsere lik distribusjon for paret?
Det er hele BNCR-idéen i én setning. Vi legger til et ekstra ledd i tap-funksjonen en KL-divergens mellom modellens output for (x_BM, y) og (x_NN, y) og vekter det med en hyperparameter λ. Vi har lånt prinsippet fra Bornea et al. (ACL 2021), som brukte det på tvers av språk; vi tilpasser det til tvers av målform.
Implementeringen er en tynn wrapper rundt HuggingFace Trainer. Det er ikke en nyrevolusjonerende arkitektur. Det er en loss-term med stop-gradient og en λ-warmup. Hele BNCR-modulen er ~150 linjer kode.
Greit, men virker det?
På Qwen 2.5-1.5B-Instruct, kjørt over tre tilfeldige seeds for å sjekke at det ikke var flaks:
| Seed | Gap-reduksjon |
|---|---|
| 1 | 50,1 % |
| 2 | 49,3 % |
| 3 | 71,5 % |
| Snitt (n=3) | 57,0 % (σ = 12,6) |
Halve gapet, snitt over tre seeds, alle tre lukker minst 49 %. Vi puttet inn 1 000 paragrafer fra Målfrid (norske offentlige dokumenter som etter loven finnes i begge målformer — gratis paret data, takk Mållovens §8) og kjørte 14 minutter på en RTX 5070 Ti.
Men er det bare data-eksponering?
Den åpenbare kritikken et reviewer-panel ville ha kommet med: "Du har bare fôret modellen mer norsk. Hvilken som helst SFT på nynorsk-tekst hadde gjort det samme."
Vi tenkte på det. Så vi kjørte ablation: akkurat samme oppskrift, men med λ = 0, altså vanlig SFT på de samme 1 000 paragrafene, uten KL-leddet.
| Variant | Gap-reduksjon |
|---|---|
| Bare SFT på Målfrid (λ=0) | 30,2 % |
| BNCR (λ=0,3) | 50,1 % |
| Det regulariseringa bidrar med | +19,9 prosentpoeng |
Så cirka 40 % av effekten av BNCR kommer fra selve regulariseringa, ikke fra at modellen så mer norsk tekst. Dataeksponering alene er en god del av historien. Men ikke hele.
Cross-scale: virker det også på 3B?
Dette er der oppskriftene vanligvis dør. De fleste fine-tuning-triks som funker på små modeller, ramler over på en større.
| Modell | Base-gap | +BNCR | Reduksjon |
|---|---|---|---|
| Qwen 2.5-1.5B (n=3) | 12,12 pp | 5,22 pp | 57 % |
| Qwen 2.5-3B | 9,16 pp | 4,84 pp | 47 % |
Samme oppskrift, samme data, samme hyperparametere. ~50 % gap-lukking på begge. Robusthet på tvers av skala er det viktigste vi viser, ærlig talt — for det er det som skiller "kult triks" fra "gjenbrukbar metode."
Det som ikke virket, og hvorfor det er den mest interessante delen
Vi testet på NorMistral-7B-warm også. Logisk neste skritt: dette er den sterkeste norsk-trente baselinjen, og den har allerede et lite gap (5,49 pp). Halver det og du er fremme.
Det skjedde ikke. Faktisk verre: gapet økte litt, og nynorsk-idiomer kollapset fra 68 % F1 til 14 % F1. Modellen hadde glemt hvordan man fullfører norske faste uttrykk.
Hvorfor? Fordi NorMistral-warm er en base-modell, ikke instruksjonstunet. Vi pakket eksemplene våre inn i Qwen sin chat-mal (<|im_start|>user … <|im_start|>assistant …), som er greit for instruktmodeller, men på en base-modell lærer det modellen at enhver fortsettelse skal se ut som en chat-respons. Den bredere generative oppførselen — den som faktisk får idiomer riktig — forsvinner.
Greit. Vi prøvde redningsforsøket: en cloze-mal designet for base-modeller — ### Svar: som skille i stedet for ChatML. Trening gikk fint. Loglikelihood-evalueringa gikk fint. Men generate_until-fasen — der modellen må produsere åpne tekster — terminerte aldri. Hver eneste idiom-prompt fortsatte til max_new_tokens ble nådd, fordi modellen hadde mistet selvtilliten på når den skulle stoppe.
Vi drepte evalueringa etter 47 minutter.
To forsøk. To forskjellige havari-typer. Samme underliggende problem: BNCR med paret tekst-trening bryter generasjonsdistribusjonen til en continued-pretraining base-modell, uavhengig av hvilken mal du pakker det i. Den indre representasjonen overlever (multiple-choice virker fortsatt fint i begge tilfeller). Det er bare generere åpen tekst-evnen som ryker.
Det er faktisk et sterkere paper-funn enn en vellykket redning ville ha vært. Det avgrenser bidraget vårt skarpt: BNCR, slik vi presenterer den, er for instruktmodeller. Punktum.
Hva betyr dette i praksis?
Hvis du driver en norsk-språklig AI-distribusjon — og det burde mange flere gjøre, både i offentlig og privat sektor då har du i 2026 cirka tre realistiske valg:
- Bruk en norsktrent base-modell (NorMistral, NorwAI-Mistral-7B, NorBLOOM). Du får liten BM/NN-skjevhet i bytte mot relativt svak engelsk og svake multilinguale evner (NorMistral scorer på sjansenivå på Belebele).
- Bruk en sterk internasjonal instruktmodell og kjør BNCR. Du får ~50 % gap-reduksjon på 14 minutter på en forbruker-GPU. Du beholder modellens generelle kapasitet. Du har en defensiv historie til styret om at AI-en din behandler bokmål og nynorsk på like vilkår — i tråd med Mållovens §1.
- Ignorer det. Mange gjør dette. Nynorsk-brukerne alle 700 000 av dem, beskyttet av grunnlovenm vil oppdage at AI-en deres er dummere enn naboens. På et tidspunkt vil noen klage til Diskrimineringsnemnda.
Vi anbefaler ikke alternativ 3.
Hva vi ikke gjorde, og hva som kommer
Dette er ikke et komplett bilde. Vi har bare kjørt full multi-seed validering på 1.5B-modellen (3B er n=1). Vi har ikke kjørt BNCR på Gemma 4 (som har et omvendt gap og Google har blandet treningsdata på en annen måte enn Mistral/Qwen-familien). Vi har ikke testet 7B+ instruktmodeller. Og vi har ikke fått BNCR til å virke på en base-modell — det er det åpenbare neste skrittet.
Vi har heller ikke kjørt head-to-head mot NorMistral sin egen continued-pretraining oppskrift. NorMistral vinner stort på absolutte tall (51,8 % bokmål mot vår BNCR-Qwen 2.5-3B sin 31,2 %). Bidraget vårt er om gap-lukking, ikke om hvilken modell som er best totalt.
Hvorfor publiserer vi dette?
Fordi det funker, det er reproduserbart på en forbruker-GPU på under en dag, koden ligger åpent, og dataene er offentlig sektor-dokumenter som du kan laste ned i kveld. Det er ingen grunn til at norske AI-distribusjoner i 2026 skulle skåre 9–12 prosentpoeng dårligere på nynorsk når en 14-minutters fine-tuning halverer det gapet.
Hvis du driver en norsk AI-distribusjon og dette er relevant, ta kontakt. Vi har koden, ablation-resultatene.