Det vi skriver
Forskningsnotater og artikler. Forskningen ligger i ro, artiklene tenker høyt, vi holder dem fra hverandre med vilje.
· Forskning
Notater fra arbeid
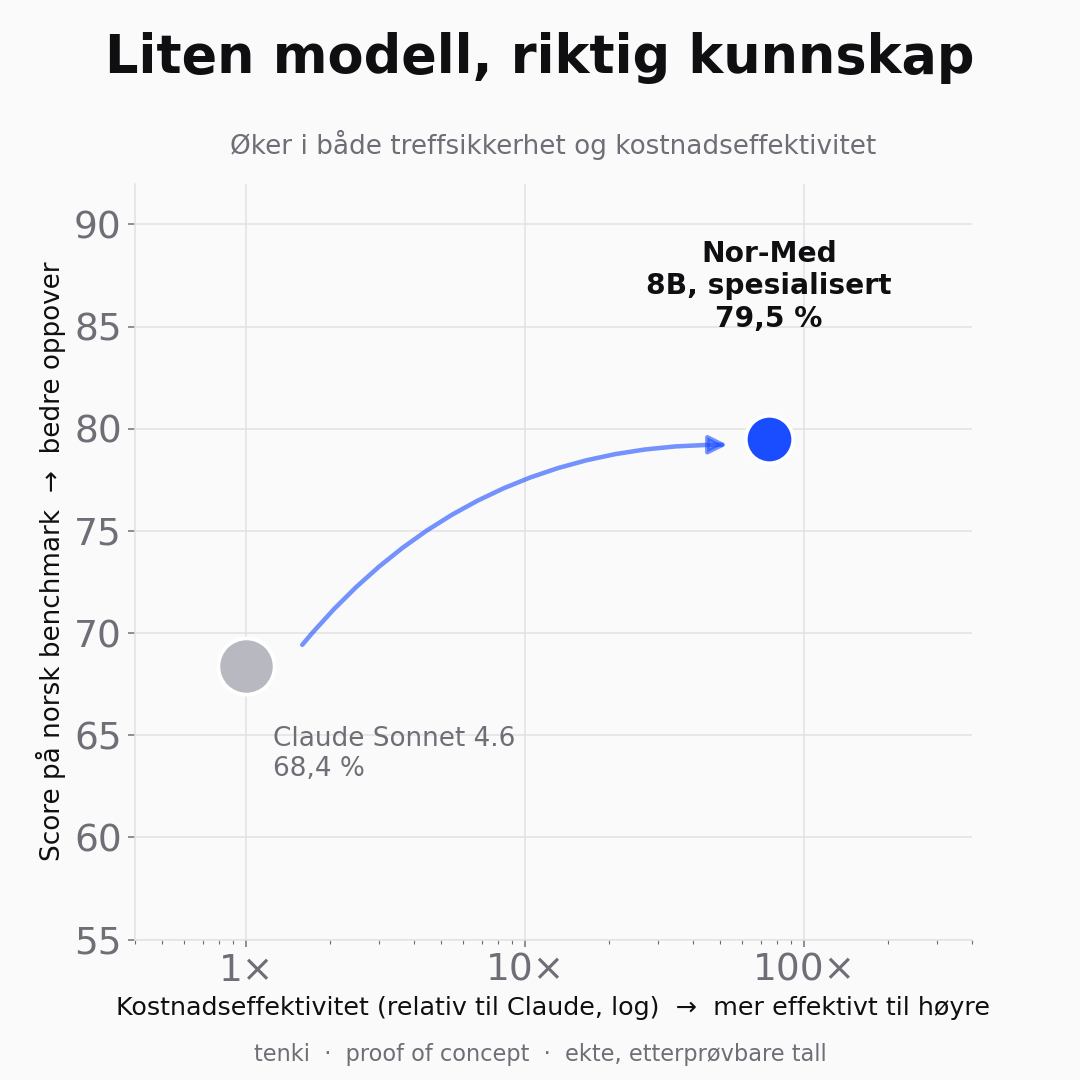
En liten spesialisert modell slår en av verdens sterkeste KI-er på norsk legemiddelrefusjon
QLoRA-finjustering av en åpen 8B-modell (Nor-Med) på blåreseptordningen slo Claude Sonnet 4.6 med 79,5 % mot 68,4 %. Et proof of concept.
Av Andreas Grønbeck
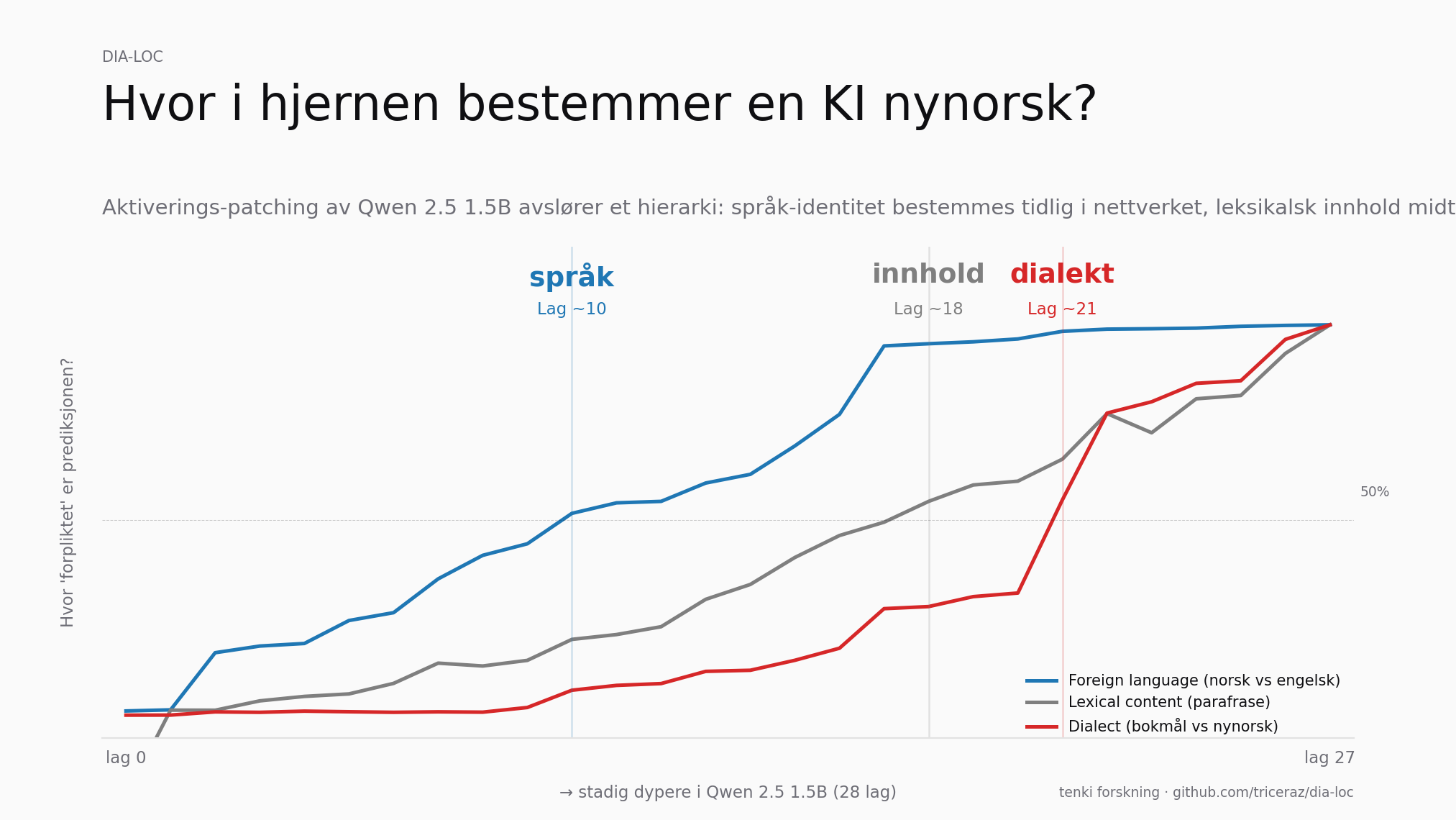
Localizing Dialect Representation in Open Norwegian-Capable LLMs
A mechanistic-interpretability look at where Qwen 2.5 commits to dialect, language, and lexical content in its residual stream
Av Andreas Grønbeck
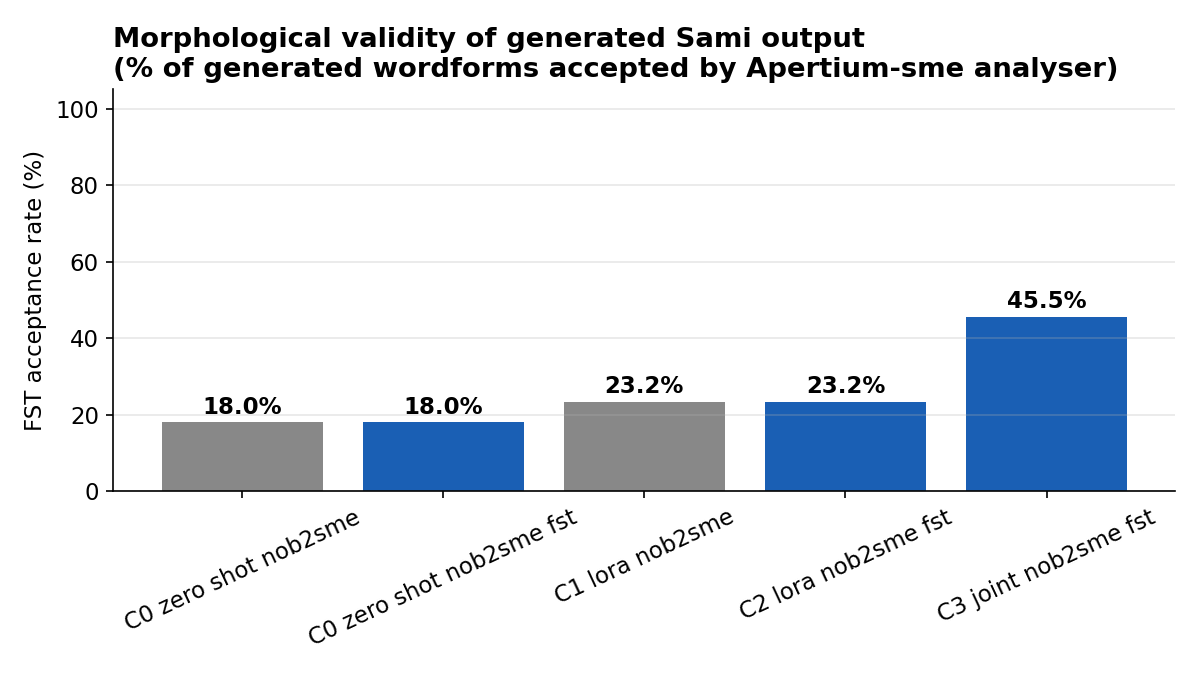
LLMs for North Sami: A Multi-Track Empirical Study of Tokenization, Translation, and Morphologically-Constrained Generation
Phase 1 release — open data, FST-aware decoding, ~6 GPU-hours on a consumer RTX 5070 Ti
Av Einar Holt
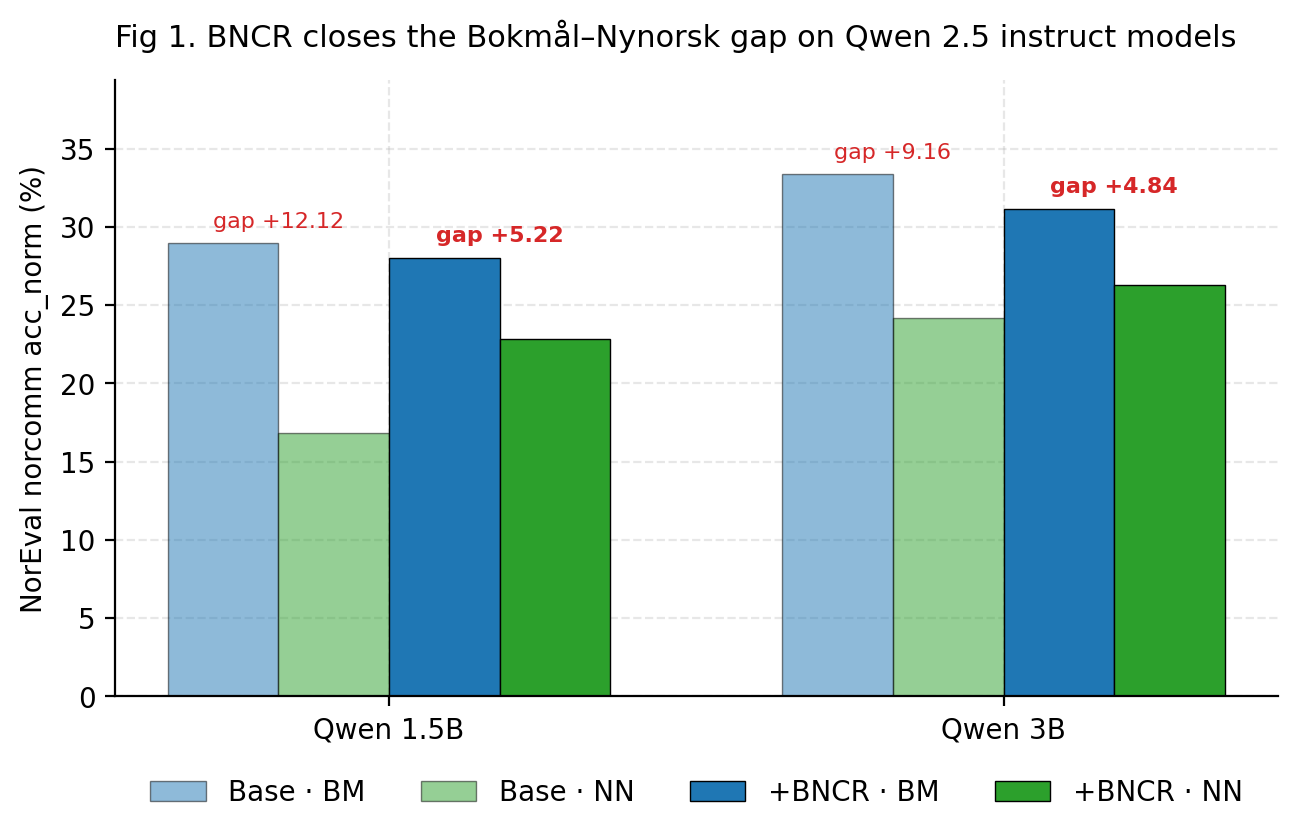
Closing the Bokmål–Nynorsk Gap: Consistency Regularization for Norwegian LLMs
BNCR — a register-invariance KL loss with multi-seed validation on Qwen 2.5
Av Einar Holt

Asymmetric-Knowledge Zero-Knowledge for Autoregressive LLM Inference (v2.1): Bootstrap CIs, Tightened Proofs, GPU-Scale Validation on Qwen 3.5, and Concurrent-Work Citation Patch
v2.1: full proofs (Claims 1, 2), N=500 bootstrap-CI experiments on RTX 5070 Ti, embedded figures, tightened limitations, and Chong et al. 2025 citation patch
Av Einar Holt
· Artikler
Det vi tenker på
- 28. mai 2026forskning
Jeg slo en av verdens sterkeste KI-modeller på norske helseregler. På en gaming-PC.
Det høres nesten for godt ut til å være sant, men jeg slo en av verdens sterkeste KI-modeller på norske helseregler. I tillegg koster modellen min en brøkdel å kjøre.
Av Andreas Grønbeck
- 15. mai 2026forskning
Jeg slo Norges beste språkforskere på en uke. Det kostet meg 47 øre.
Jeg er 20 år gammel, NTNU-student, og driver tenki ved siden av studiene. For en uke siden bestemte jeg meg for å se om jeg kunne lage en bedre norsk språkmodell enn de som finnes. Resultatet, Hugin 2 4B 4-bit, slår NorMistral 7B Warm fra Universitetet i Oslo på 7 av 9 standardiserte norske benchmarks. På leseforståelse er gapet 50 prosentpoeng. Treningen kostet 47 øre i strøm.
Av Einar K. Holt
- 11. mai 2026kunstig intelligens
Hvorfor hallusinerer kunstig intelligens?
Hver gang en språkmodell svarer deg, sampler den det neste mest sannsynlige token-et fra en sannsynlighetsfordeling. Den har ingen sannhetsmåler innebygd, bare en koherens-måler. Det betyr at riktig spørsmål ikke er hvorfor den hallusinerer noen ganger, men hvorfor den noen gang treffer. I denne artikkelen ser vi på hallusinering som tapsbasert kompresjon og som nevrologisk konfabulering, og hvorfor de to bildene sammen peker mot RAG som en naturlig grense, ikke en lapp.
Av Einar K. Holt
- 10. mai 2026forskning
Vi spurte en KI hvor den «tenker» nynorsk. Svaret kom helt mot slutten.
Tenk på en KI-modell som en bygning med 28 etasjer. På bunnetasjen kommer setningen din inn som rå tekst, på toppen kommer svaret ut. Vi målte hvor i bygningen modellen faktisk bestemmer at svaret skal være på nynorsk og ikke bokmål, og fant et hierarki av forpliktelser: språk avgjøres tidlig, innhold midt, dialekt sist.
Av Andreas Grønbeck
- 9. mai 2026forskning
AI-en din forstår dansk bedre enn nynorsk. Vi halverte gapet.. på én kveld.
Hver eneste Qwen-modell vi testet svarer 9–12 prosentpoeng dårligere på nynorsk enn på bokmål. Det er ikke et lite avvik — det er at AI-en gjør LO-skole-feil hver gang en bruker skriver i målform som halve Vestlandet bruker. Her er hva vi prøvde, hva som funket, og hva som spektakulært gikk i bakken.
Av Einar K. Holt
- 6. mai 2026forskning
Hvorfor vi bygger nullkunnskapsbevis for språkmodeller
Av Einar K. Holt
- 1. mai 2026Næringsliv & strategi
Paradigmeskifter blir alltid avvist mens de skjer
En forskningsrapport om kunstig intelligens jeg skrev på videregående i 2023 ble avvist som irrelevant. En oppgave om bakterier på skoletoalettene kom gjennom. Tre år senere gjør norsk næringsliv den samme feilen i langt større skala, og det handler ikke om et nytt verktøy. Det handler om hvordan paradigmeskifter blir møtt før noen har innsett at de er paradigmeskifter.
Av Einar K. Holt
- 1. mai 2026AI-Benchmarking
Benchmark-tall lyver ikke, men de forteller heller ikke sannheten
ARC-AGIs nye leaderboard viser score og kostnad per oppgave. o3-preview løste 75% av ARC-AGI-1, men til over 200 dollar per oppgave. Mennesker løser det samme til 17 dollar.
Av Andreas Grønbeck
- 26. apr. 2026AI-infrastruktur
Hvorfor vi gikk vekk fra Mac mini
Vi har testet Mac mini, Mac Studio og NVIDIA DGX Spark for lokal AI hos norske SMB-er. Etter måneder i produksjon har vi en mening om hvorfor Spark vant, hva som skjer når du kobler den mot en kraftig workstation, og hvorfor det får oss til å lure på hva en ansatt egentlig er.
Av Einar K. Holt