forskning
Jeg slo en av verdens sterkeste KI-modeller på norske helseregler. På en gaming-PC.
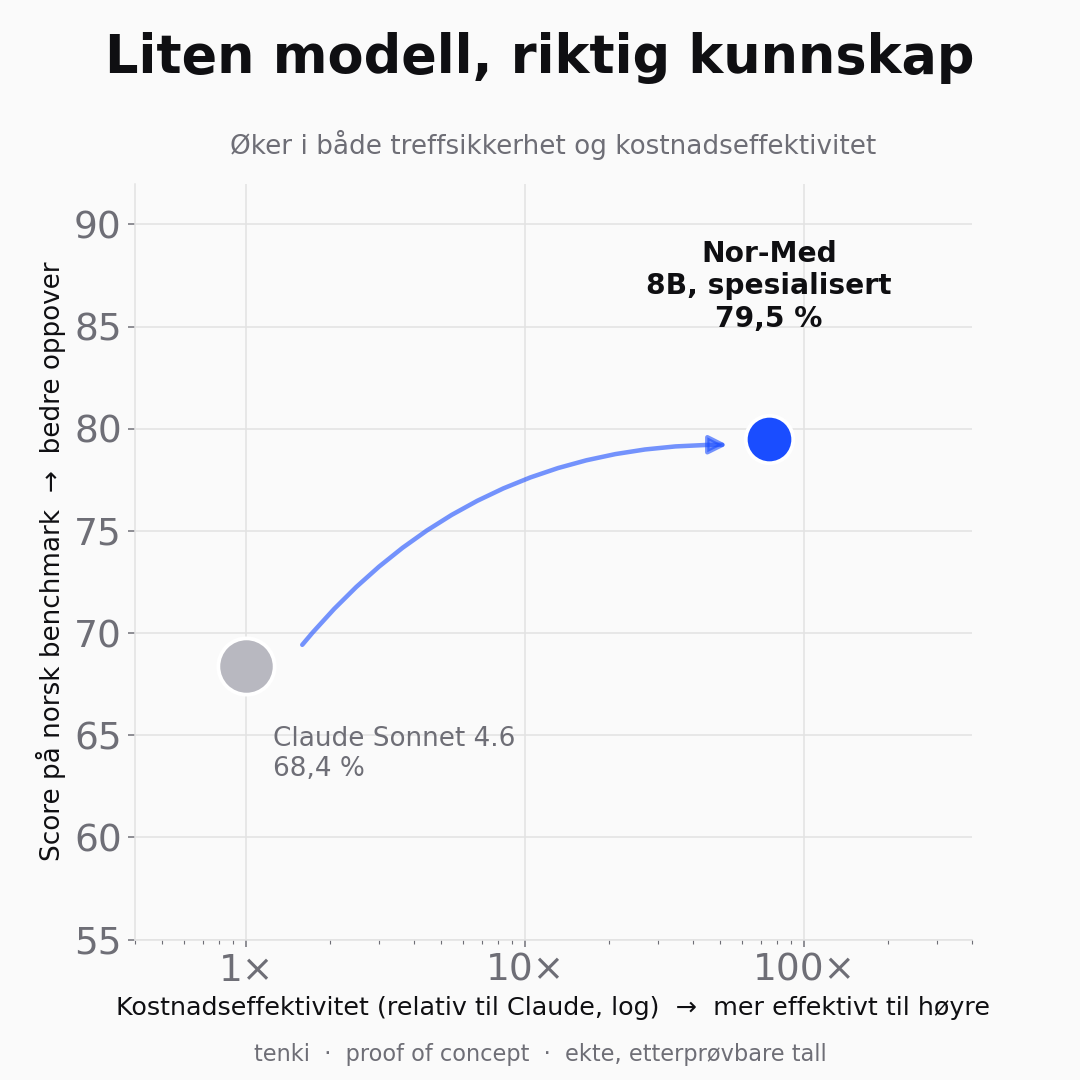
Et proof of concept: en spesialisert 8B-modell (Nor-Med) slo Claude Sonnet 4.6 på norsk legemiddelrefusjon.
 Andreas GrønbeckKI-Ingenør · 28. mai 2026
Andreas GrønbeckKI-Ingenør · 28. mai 2026Det høres nesten for godt ut til å være sant, men jeg slo en av verdens sterkeste KI-modeller på norske helseregler. I tillegg koster modellen min en brøkdel å kjøre.
La meg være tydelig med en gang på hva dette ikke er: Jeg har ikke laget en bedre KI-modell enn Anthropic eller OpenAI. Det kunne jeg aldri klart, og det er ikke poenget. Dette er et proof of concept. Det er ikke produksjonsklart, det er ikke testet på ekte pasientdata, og det skal ikke brukes i en klinisk hverdag uten mye mer arbeid.
Men innenfor de rammene viser eksperimentet noe jeg mener er viktig: en liten, spesialisert modell kan gjøre svært verdifullt arbeid på konkrete norske oppgaver, og slå selv de største generelle modellene på sitt eget hjemmebane.
Eksperimentet
Jeg laget et fagspesifikt benchmark på 42 oppgaver om blåreseptordningen, regelverket som styrer hvilke legemidler staten dekker, under hvilke vilkår, hvem som kan søke, og hva pasienten betaler i egenandel. Det er et regelverk som endrer seg ofte, og som er fullt av detaljer og kontraintuitive unntak.
Så ga jeg de samme 42 spørsmålene til Claude Sonnet 4.6, en av verdens sterkeste modeller, i en helt fersk økt uten tilgang til fasiten. Den scoret 68,4 %.
Deretter finjusterte jeg en åpen modell, Qwen3-8B (8 milliarder parametere), på rundt 200 treningseksempler om blåresept. Den spesialiserte modellen kaller jeg Nor-Med. Treningen kjørte på min egen RTX 3060 Ti, et helt vanlig gaming-grafikkort, på noen timer.
Resultatet: 79,5 %. Over 11 prosentpoeng bedre enn Claude.
| Modell | Score |
|---|---|
| Claude Sonnet 4.6 (fersk økt) | 68,4 % |
| Nor-Med (min spesialiserte 8B-modell) | 79,5 % |
Hvorfor vinner den lille modellen?
Ikke fordi den er smartere. Den vinner fordi den kan faktaene. Claude bommet systematisk på norske regelendringer som kom etter modellens kunnskapsgrense:
- Når opphørte den offentlige finansieringen av Paxlovid? Claude svarte november 2023. Riktig svar: 1. april 2025.
- Når ble § 3a erstattet av ny § 3? Claude svarte februar 2024. Riktig svar: 17. juni 2025.
- Hva er egenandelen i 2026? Claude oppga de gamle satsene. Riktig svar: 60 %, maks 400 kr.
Den generelle modellen kan ikke svare på det den aldri har lært, og den kan ikke vite hva som endret seg etter at den ble trent. Den spesialiserte modellen lærte akkurat disse faktaene.
Et morsomt sidefunn: Jeg testet også modellen med oppslag (RAG), der den får hente inn relevante kildetekster før den svarer. Det gjorde den faktisk dårligere (77,1 %). Når faktaene allerede sitter i modellvektene, ble støyete oppslag bare forvirrende. Det er en nyttig påminnelse om at mer maskineri ikke automatisk er bedre.
Det egentlige poenget
Verdien i anvendt KI kommer sjelden fra rå modellstyrke alene. Den kommer fra samsvar mellom modellen og oppgaven. En mindre modell som kan oppgaven, slår en større modell som ikke gjør det.
Dette er et argument mot en refleks jeg ser ofte: å dele ut Copilot-lisenser til alle som vil ha, uten noen oppbygging av kompetanse eller tilpasning, og forvente at verdien skal rulle inn av seg selv. Det er feil rekkefølge. Tilgang er ikke verdi. Verdi er noe man bygger.
Og det handler om mer enn produktivitet. For et lite land med eget språk, eget lovverk og egne forvaltningsregler er evnen til å spesialisere åpne modeller lokalt også et spørsmål om suverenitet. Kode24 har skrevet godt om nettopp dette. Les gode grunner til å utvikle norske modeller, ikke minst suverenitet. Dette eksperimentet er det samme argumentet på teknisk nivå: en liten modell du forstår og kontrollerer kan være mer verdifull enn en stor modell du er helt avhengig av.
Ærlig om begrensningene
Jeg vil ikke overselge dette. Benchmarken er laget av meg selv, så samsvaret mellom trening og test er høyere enn det ville vært med et uavhengig testsett. Evalueringsmetoden for de åpne spørsmålene er enkel (nøkkelord-overlapp), ikke en grundig faglig vurdering. Tallene er ekte og kan etterprøves, men de er et utgangspunkt for en idé, ikke en endelig måling.
Det dette beviser er rett og slett dette: terskelen for å bygge noe meningsfylt med KI er mye lavere enn folk tror. Og noen burde gjøre det.