forskning
Vi spurte en KI hvor den «tenker» nynorsk. Svaret kom helt mot slutten.
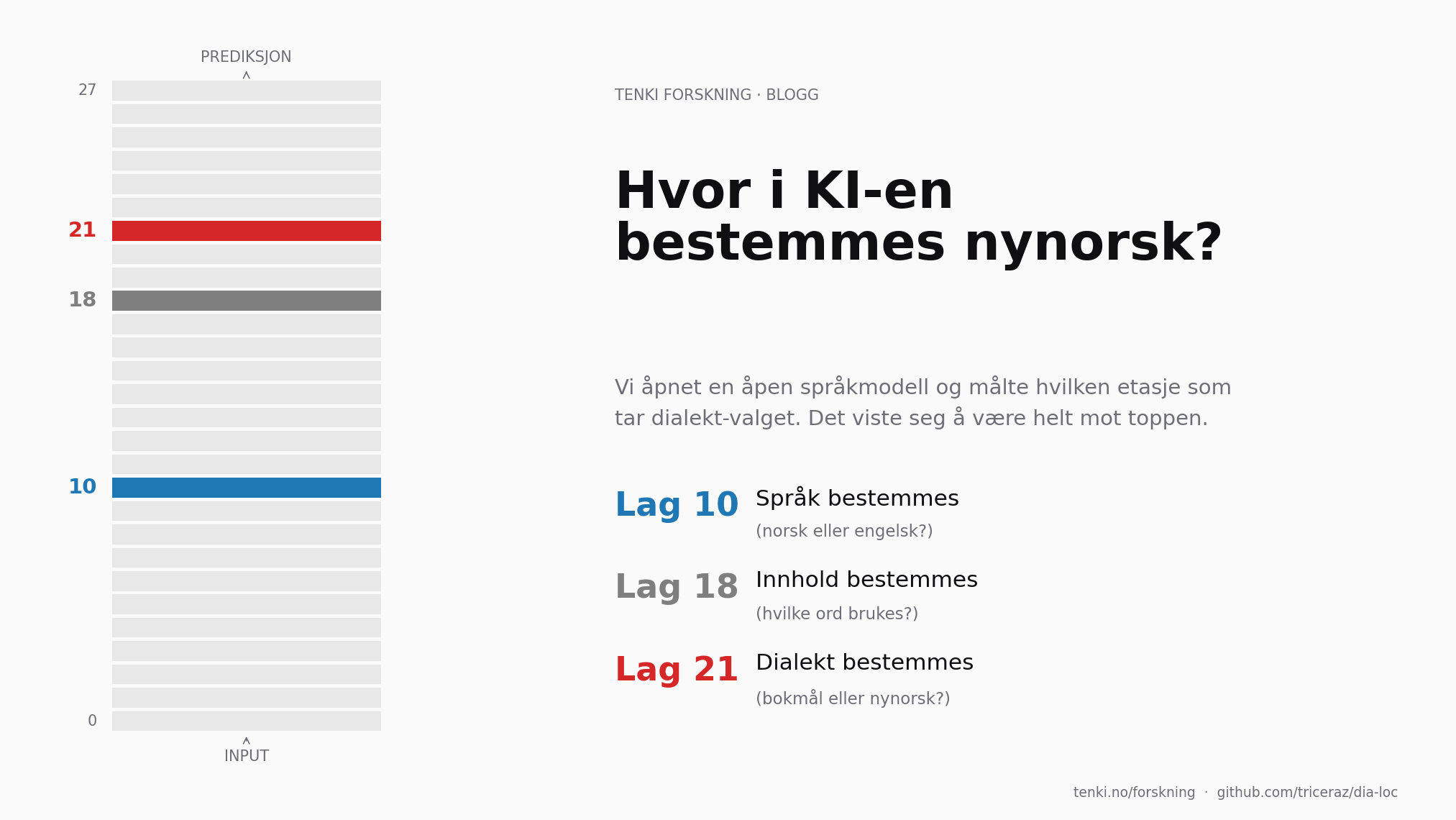
Vi åpnet en åpen språkmodell og målte i hvilken etasje av nettverket dialekt-valget faktisk tas. Det skjer i lag 21 av 28.
 Andreas GrønbeckKI-Ingenør · 10. mai 2026 · 3 min lesing
Andreas GrønbeckKI-Ingenør · 10. mai 2026 · 3 min lesingTenk på en KI-modell som en bygning med 28 etasjer. På bunnetasjen kommer setningen din inn som rå tekst, på toppen kommer svaret ut. Vi målte hvor i bygningen modellen faktisk bestemmer at svaret skal være på nynorsk og ikke bokmål, og fant et hierarki av forpliktelser: språk avgjøres tidlig, innhold midt, dialekt sist.
Tenk på en KI-modell som en bygning med 28 etasjer. På bunnetasjen kommer setningen din inn som rå tekst. På toppen kommer svaret ut, formulert. Mellom dem skjer all jobben: ord brytes ned, mening pakkes sammen, og til slutt bestemmer modellen hva neste ord skal være.
Vi stilte oss et enkelt spørsmål: i hvilken etasje bestemmer modellen at svaret skal være på nynorsk og ikke bokmål?
Svaret er etasje 21. Av 28.
Hva vi gjorde
Vi tok en åpen språkmodell, Qwen 2.5 1.5B, og kjørte tre slags par-setninger gjennom den:
- Bokmål mot nynorsk (samme setning, ulik målform)
- Bokmål mot engelsk (samme setning, ulikt språk)
- Bokmål mot bokmål (parafraser med samme mening, andre ord)
Den siste gruppa er kontrollen. Hvis modellen «skiller» mellom de to bokmål-versjonene like sterkt som mellom bokmål og nynorsk, har vi ikke målt dialekt — vi har målt at orda er forskjellige.
For hver av de 28 etasjene målte vi: hvis vi tar det modellen «tenker» på etasje N for nynorsk-versjonen og bytter det inn i bokmål-versjonen, blir prediksjonen nynorsk-aktig nå?
Hvis ja, da er det denne etasjen som tar avgjørelsen.
Hva vi fant
| Bestemmes på etasje | ||
|---|---|---|
| Engelsk eller norsk? | 10 | tidlig |
| Hvilke ord skal brukes? | 18 | midt |
| Bokmål eller nynorsk? | 21 | sent |
Modellen forplikter seg til språk tidlig i bygningen. Den forplikter seg til innhold i midten. Og den forplikter seg til dialekt helt mot slutten.
Det er et representasjons-hierarki vi ikke visste eksisterte før vi målte. Modellen skiller mellom oppgavene «hvilket språk er dette?» og «hvilken målform skal det være?» som om det var to forskjellige avgjørelser, tatt på forskjellige tidspunkt.
Hvorfor det betyr noe
For Tenki, som lager Hugin (modellen som svarer på tenki.no/chat) og jobber med norsk lokal-KI for bedrifter, gir dette praktisk veiledning. Vil vi at en KI-modell skal bli flinkere på nynorsk, må vi intervenere på de øverste etasjene. En endring i etasje 5 ville være feil sted.
For folk som tenker på KI mer generelt, sier funnet noe om at språk- og dialekt-valg ikke er ett samlet «velg utgang»-trinn. Det er en sekvens av forpliktelser, og dialekt er det siste laget — det mest skjøre, det som lettest kan bli «glemt» av modellen i favør av bokmål.
Hva vi ikke sier
Vi har bare testet én modell-familie (Qwen 2.5, 1.5B og 3B) — vi har ikke testet Gemma 3 4B, modellen som faktisk kjører Hugin i produksjon. Det neste steget. Vi har heller ikke testet om naturlig nynorsk (chat-stil, ikke maskinoversatt) gir samme bilde. Og kanskje viktigst: vi måler hvor modellen forplikter seg, ikke om svaret den til slutt gir er godt nynorsk. Det er to forskjellige spørsmål.
Hvor finner du resten
Hele forskningsartikkelen ligger på tenki.no/forskning/dia-loc. Kildekoden, dataene, og alle figurene er åpent tilgjengelig på github.com/triceraz/dia-loc. Du kan reprodusere alt fra null på et halvt billig grafikkort på rundt 30 minutter.